[Alg] Greedy search
17 Jan 2020
(Codility 내용 기반으로 포스트를 작성합니다. Greedy altorighm 관련한 좋은 자료는 아래를 참고 부탁 드립니다.)
Greedy 알고리즘은 단순하면서도 직관적인 알고리즘 입니다. Greedy 알고리즘은 모든 problem에 통하지는 않지만 Huffman encoding이라든지, Dijkstra’s algorithm에서 shortest path를 찾는 경우 훌륭하게 동작합니다.
Greedy Algorithm
Not suited problems
아래 두 problem은 대표적으로 Greedy algorithm이 적용되지 않는 problem 입니다. 바로 Graph에서 최적 해를 찾는 문제와 Kanpsack problem 입니다. 한번 살펴 보겠습니다.
Graph
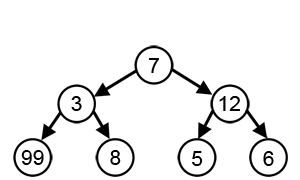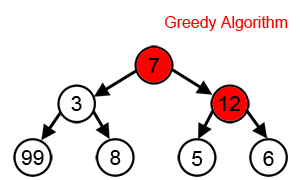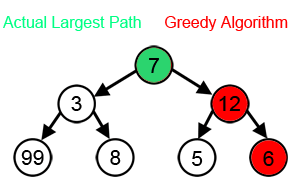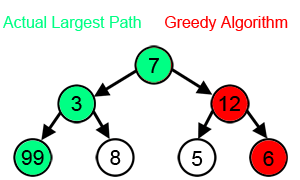
위의 그림에서 보다시피 Greedy algorithm은 많은 problem에서 최적의 결과를 얻어내지 못합니다. 실제 largest path 는 7->3->99 이지만, Greedy algorithm이 선택하는 Path는 7->12->6 입니다. 즉 그래프를 search하면서 값이 큰 쪽으로 search를 해 나가기 때문에 발생하는 결과 입니다. 최적의 결과를 얻지 못한 것이죠.
Knapsack problem
| Item | Price | Size | |—|—|—| |Laptop | 12 | 22 | |Playstation | 9 | 10 | |TextBook | 9 | 9 | |Basketball | 6 | 7|
Kapsack problem도 Greedy algorithm이 적용되지 않는 케이스 중 하나입니다. 가방에 최대 price의 물건을 담는 것이 목표라고 해보죠. 가방 크기가 25라고 해 봅시다. Large price 기준으로 Greedy algorithm을 돌리면 Laptop 하나만 들어갈 것 입니다. 이미 laptop의 크기가 22이기에 이후 어떠한 물건도 넣을 수 없습니다. (25 - 22 = 3). 결과는 12 price를 넣을 수 있었습니다.
가장 작은 size의 물건들을 넣는 방식은 어떨까요? basketball - textbook 순으로 넣을 수 있을 것 같습니다. basketball 과 textbook의 size가 16이니 이 2개를 넣으면 나머지를 넣지 못하겠네요. 결과는 16 입니다.
하지만 최적의 값을 갖고오는데 있어 Greedy algorithm은 역시 실패했습니다. 최적은 textbook + playstation이군요. (18 price)
이제 Greedy algorithm이 소위 먹히는?! algorithm에 대해서 보겠습니다.
Well suited problem
아래 두 problem은 Greedy algorithm을 사용해 최적해를 얻어낼 수 있습니다.
Huffman Code
Huffman Code:(https://brilliant.org/wiki/huffman-encoding/) 가변길이(Variable-length) encoding으로 symbol을 표현하는 방식입니다. 자주 나오는 단어에는 짧은 bit으로 encoding하고, 드물게 나오는 단어에는 긴 bit으로 encoding을 해 줍니다.
주의해야 할 것이 표현되는 encoding scheme이 모호하지 말아야 한다는 것인데요. 아래 예를 한번 보겠습니다.
| A | B | C | D |
|---|---|---|---|
| 0 | 1 | 11 | 10 |
예를 들어 각 A,B,C,D가 0,1,11,10으로 encoding된다고 합니다. 일단 encoding bits들은 모두 unique한 것 같습니다.
아래 2개의 단어를 encoding해볼 것 입니다.
BAC
DC
인코딩 결과가 어떤지 보겠습니다.
1011
1011
encoding 결과 둘 다 똑같은 bits로 encoding 되었습니다. 가변길이 encoding (variable-length encoding)은 이러한 모호성을을 갖기 쉽습니다. 따라서 encoding bits를 생성할 때 주의를 기울여야 하는데요. 이 때 사용되는 algorithm이 Greedy algorithm 입니다.
Huffman은 greedy algorithm을 이용해,
- 자주 나오는 단어들에는 적은 양의 bits를, 적게 나오는 단어들에 대해서는 상대적으로 많은 bits가 할당되는 algorithm을 만들어 낼 수 있습니다. [Huffman prefix tree]:(https://brilliant.org/problems/encoding-trees-1/#)를 만드는 방법은 링크를 참고해 주세요.
- 또한 각 tree에서 나오는 prefix 값은 다른 prefix 값들과 반드시 다른 값이 나오게 되고 위의 모호성 문제도 해결됩니다.
Dijkstra’s algorithm
노드와 노드 사이의 shortest path를 구하는 알고리즘 입니다. 여기에서도 Greedy algorithm 이 사용될 수 있는데요.

-
출발 노드와 연결된 노드들 중 가장 거리가 짧은 노드를 선택하여 이동합니다. (Greedy) 하지만 위와 같이 각 노드들에서 짧은 path만 선택하여 가다보면, 즉 Node(1) -> Node(2) -> Node(3) 으로 이동하면 Node(3)에 도착하기 까지 path의 총 weight의 합은 17이 됩니다. 하지만 Node(1) -> Node(3)은 9로서 훨씬 가깝습니다. 이 때는 Node(1) -> Node(3)이 shortest path가 됩니다.
-
Node(3) -> Node(6)으로 가보죠. 9 + 2 = 11이니 Node(1) -> Node(6)의 14보다는 작네요. 일단 Node(6)까지의 shortest path는 Node(1) -> Node(3) -> Node(6) 입니다.
Node(3) -> Node(4)는 Node(3) -> Node(6)보다 거리가 길어서 우선 선택되지 못하였습니다.
-
Node(6) 에서 Node(5) 길이 있고 그 weight은 9 입니다. 일단 목적지 Node(5)에 도착했습니다. 끝이 아닙니다. 이제 순회하지 않은 나머지 최선이 아닌, 차선책이었던 Node들에 대해서 동일하게 위의 1번과 같이 그 다음 짧은 노드를 선택하여 목적지까지 도착하게끔 합니다.
-
이제 목적지 까지 도달한 shortest path중 가장 짧은 것을 선택하면 됩니다.
Dijkstra가 이 알고리즘을 고안하는데 걸린 시간은 단 5분이라는 얘기가 있더군요. 알고리즘을 swift로 작성하면서 많은 자괴감(?)이 들었습니다. 뭐 물론 말로 설명하는 것과 source를 짜는 것은 엄연히 다르다는 생각을 하며 스스로를 위로했습니다. Dijkstra’s algorithm for swift에서 좀 더 깊이있게 살펴보겠습니다.